2. 통계로 본 생존의 조건, 숫자 속에 숨어 있는 이야기#
데이터 과학 동아리 - 두 번째 모임
프롬: 다안 선배, 지난 시간에 타이타닉 데이터의 기본 구조를 살펴봤는데, 오늘은 어떤 걸 알아볼 예정인가요?
다안: 지난 시간에 우리는 데이터 파일들의 구조와 내용을 확인했지. 그리고 성별만으로도 76.555%의 정확도를 달성할 수 있다는 사실도 발견했어. 오늘은 한 걸음 더 나아가 데이터를 좀 더 깊이 분석해볼 거야.
코더블: 그러니까 좀 더 다양한 변수들이 생존율과 어떤 관계가 있는지 살펴볼 거군요?
다안: 정확해! 모델을 만들기 위해서는 먼저 데이터를 깊이 있게 이해하는 것이 중요해. 우리가 가진 train 데이터에는 어떤 패턴이 있을까? 수치로 표현된 특성들(나이, 요금, 동승한 가족 수 등)은 생존과 어떤 관계가 있을까? 이런 질문들에 대한 답을 찾아가면서, 자연스럽게 첫 번째 머신러닝 모델을 만들어 볼 거야.
코더블: 먼저 데이터를 읽어와야 할 텐데, 지난 시간에 했던 것처럼 코드를 작성할게요.
import pandas as pd
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
submission = pd.read_csv('gender_submission.csv')
다안: 좋아, 이제 데이터를 불러왔으니 분석을 시작해보자!
데이터의 기본 정보 확인#
프롬: 데이터에 대해 좀 더 자세히 알아보고 싶은데, 어떤 정보를 먼저 확인하면 좋을까요?
다안: 데이터를 처음 마주했을 때 가장 먼저 해야 할 일은 전반적인 특성을 파악하는 거야. pandas는 이를 위한 유용한 함수들을 제공해. 예를 들어, info() 함수를 사용하면 데이터의 기본 정보를 한눈에 볼 수 있지.
코더블: info() 메서드로 확인해볼게요. 이 메서드는 데이터프레임의 요약 정보를 보여주는데, 컬럼 이름, 데이터 타입, 결측치 등을 확인할 수 있어요.
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
프롬: 코드가 간단하네요! info()만 쓰면 이렇게 많은 정보를 볼 수 있다니 신기해요.
다안: 좋아, 이제 데이터의 구조가 더 명확해졌네. 출력 결과를 보면 몇 가지 중요한 사실을 알 수 있어:
프롬: 총 891명의 승객 정보가 있고, 어떤 정보들은 누락되어 있네요. 특히 나이(Age)는 714명만 있고, 객실 번호(Cabin)는 거의 대부분 빠져있어요!
다안: 잘 관찰했어! 나이(Age) 정보는 891명 중 714명만 있고, 177명의 정보가 빠져있어. 그리고 객실 번호(Cabin)는 더 심각해서, 891명 중 204명의 정보만 있지. 또 정보의 형태도 다양해. 숫자로 된 정보(나이, 요금, 동승자 수 등)와 글자로 된 정보(이름, 성별, 객실 번호 등)가 섞여있어.
코더블: 이렇게 빠진 데이터를 결측치(missing value)라고 하죠? 실제 분석을 위해서는 결측치 개수를 정확히 확인하는 게 중요하니, isnull().sum() 코드로 각 컬럼별 결측치를 확인해볼게요.
train.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
다안: 좋은 제안이야! 이렇게 각 컬럼별 결측치 개수를 정확히 파악하면 데이터 전처리 계획을 세우는 데 도움이 돼. 이러한 결측치가 있다는 것은 나중에 특별한 처리가 필요하다는 신호야. 특히 나이 정보가 꽤 많이 빠져있네. 이 부분은 나중에 자세히 다루어보도록 하자.
숫자로 된 정보들의 특징 파악#
프롬: 이제 데이터의 기본 구조를 알았으니, 숫자로 된 정보들에 대해 좀 더 자세히 알아보고 싶어요. 어떤 통계 정보를 얻을 수 있을까요?
다안: 좋은 질문이야! 숫자로 된 데이터는 평균, 최소값, 최대값 같은 통계적 특성을 계산할 수 있어. pandas에서는 describe() 함수를 사용하면 이런 정보를 한 번에 얻을 수 있지.
프롬: 그럼 프롬프트로 확인해볼게요!
# 프롬프트
train 데이터의 숫자로 된 정보들의 통계적 특성을 보여줘
코더블: 저는 describe() 메서드를 사용해서 확인해볼게요.
train.describe()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
다안: 훌륭해! 이 결과에서 몇 가지 중요한 정보를 확인할 수 있어:
프롬: 생존율이 38.4%네요. 약 3명 중 1명만 살아남았다는 의미인가요?
코더블: 맞아요, describe() 결과를 보면 Survived 컬럼의 평균값이 0.384인데요. Survived가 생존=1, 사망=0으로 표시된 변수이니까, 이건 생존자 비율이 38.4%라는 의미예요. 정확하게 891명 중 342명이 생존했다는 계산이 나오네요.
다안: 정확해! 코더블이 잘 설명했어. Survived 값의 평균이 0.384라는 건 전체 승객의 38.4%가 생존했다는 의미야. 약 3명 중 1명 정도만 생존한 셈이지. 이건 침몰하는 배에서 살아남기가 얼마나 어려웠는지를 보여주는 중요한 통계야. 891명의 승객 중 342명만 살아남고, 549명은 바다에서 생을 마감했다는 거야.
💡 describe() 결과 해석 요약
생존율: 전체 승객의 38.4% 생존 (Survived mean: 0.384)
나이 분포: 평균 29.7세, 최소 0.42세(영아), 최대 80세(노인)
객실 등급: 평균 2.31로, 2등급과 3등급 승객이 더 많음
요금 분포: 평균 32.2파운드, 최대 512.3파운드
동승 가족수: 형제/배우자(SibSp) 평균 0.5명, 부모/자녀(Parch) 평균 0.38명
코더블: 나이 분포도 흥미롭네요. 가장 어린 승객은 아기(0.42세)였고, 가장 나이 많은 승객은 80세였어요. 그리고 요금은 정말 차이가 크군요, 무료부터 512파운드까지!
다안: 좋은 관찰이야! 나이 분포를 보면, 평균 나이는 29.7세였고, 절반의 승객들이 20세에서 38세 사이였어. 그리고 요금 분포는 정말 넓지. 평균 요금은 32.2파운드였지만, 무료로 탑승한 승객부터 512.3파운드를 지불한 승객까지 있었어. 이런 큰 요금 차이는 객실 등급과 관련이 깊을 거야.
프롬: 요금이 512파운드라니, 현재 가치로 얼마나 되는 걸까요?
다안: 1912년 당시 512파운드는 현재 가치로 약 1억 3천만 원 정도 돼. 이렇게 통계 정보를 보면 데이터 속에 숨겨진 이야기들을 발견할 수 있어.
글자로 된 정보들의 특징 파악#
코더블: 그런데 데이터에는 숫자뿐만 아니라 문자형 데이터도 있잖아요. 이런 글자로 된 정보들은 어떻게 분석할 수 있을까요?
다안: 좋은 질문이야! 문자열(object) 타입 컬럼들의 특성도 살펴볼 수 있어. describe() 함수에 include=’object’ 파라미터를 추가하면 문자열 데이터에 대한 기본 통계를 확인할 수 있지.
코더블: describe() 메서드에 include=’object’ 파라미터를 추가해서 문자열 데이터를 확인해볼게요.
train.describe(include='object')
| Name | Sex | Ticket | Cabin | Embarked | |
|---|---|---|---|---|---|
| count | 891 | 891 | 891 | 204 | 889 |
| unique | 891 | 2 | 681 | 147 | 3 |
| top | Braund, Mr. Owen Harris | male | 347082 | B96 B98 | S |
| freq | 1 | 577 | 7 | 4 | 644 |
프롬: 숫자 데이터와는 다른 종류의 통계가 나오네요. 각 값이 무슨 의미인지 설명해주실 수 있나요?
다안: 그럼! 문자열 데이터에 대해서는 다른 종류의 통계가 제공돼:
count: 결측치가 아닌 값의 개수
unique: 고유한 값의 개수
top: 가장 많이 등장하는 값
freq: top 값의 등장 횟수
프롬: 결과를 보니까, 성별(Sex)은 ‘male’과 ‘female’ 두 가지 값만 있고, ‘male’이 더 많네요. 그리고 승선 항구(Embarked)는 대부분 ‘S’인 것 같아요.
다안: 맞아! 결과를 보면 성별(Sex)은 ‘male’과 ‘female’ 두 가지 값만 있고, 승선 항구(Embarked)는 대부분 ‘S’(Southampton)야. 객실 번호(Cabin)는 종류가 매우 다양하고, 같은 번호를 쓰는 경우도 거의 없네. 이름(Name)은 당연히 모두 다르고.
코더블: 소름 돋아요. 실제 존재했던 사람들의 이름이잖아요…
다안: 맞아, 그게 타이타닉 데이터의 특별한 점이야. 우리가 분석하는 건 단순한 숫자가 아니라 실제 역사 속 인물들의 이야기니까.
Note
코드 생성의 가변성에 대하여
프롬프트를 통해 코드를 생성할 때 알아두면 좋을 점들이 있습니다:
이 책에 있는 프롬프트를 그대로 입력하더라도 책과 완전히 동일한 코드가 생성되지 않을 수 있습니다. 이는 자연스러운 현상입니다:
사용하는 인공지능 모델에 따라 다른 코드가 생성될 수 있습니다
같은 모델이라도 버전이 다르면 다른 코드를 제시할 수 있습니다
심지어 같은 모델, 같은 버전이라도 매번 다른 코드를 생성할 수 있습니다
생성된 코드가 책의 코드와 다르더라도, 실행 결과는 책의 내용을 이해하는 데 무리가 없습니다
책의 설명을 더 명확하게 하기 위해 프롬프트나 코드를 일부 수정한 경우도 있습니다
원하신다면 책에 있는 코드를 그대로 복사해서 사용해도 됩니다
결과적으로 동일한 분석 목표를 달성할 수 있다면, 어떤 방식을 선택하든 무방합니다.
생존율 시각화하기#
프롬: 지금까지는 숫자로 된 정보들을 보기만 했는데, 이걸 그래프로 시각화하면 더 이해하기 쉬울 것 같아요. 특히 생존자와 사망자의 비율을 그래프로 볼 수 있을까요?
다안: 아주 좋은 생각이야! 시각화는 데이터 분석에서 매우 중요한 부분이지. 전체 승객 중 생존자의 비율을 파이그래프로 표현하면 한눈에 알아보기 쉬울 거야.
프롬: 제가 프롬프트로 파이그래프를 만들어볼게요!
# 프롬프트
전체 승객 중에서 생존자가 몇 명이나 되는지 파이그래프로 보여줘
코더블: 저는 matplotlib 라이브러리를 사용해서 파이그래프를 만들어볼게요. 먼저 생존 여부를 카운트한 다음 파이그래프로 표현하면 돼요.
import matplotlib.pyplot as plt
survival_counts = train['Survived'].value_counts()
plt.figure(figsize=(6, 6))
plt.pie(survival_counts, labels=['Deceased', 'Survived'], autopct='%1.1f%%', startangle=90)
plt.title('Survival Rate')
plt.show()
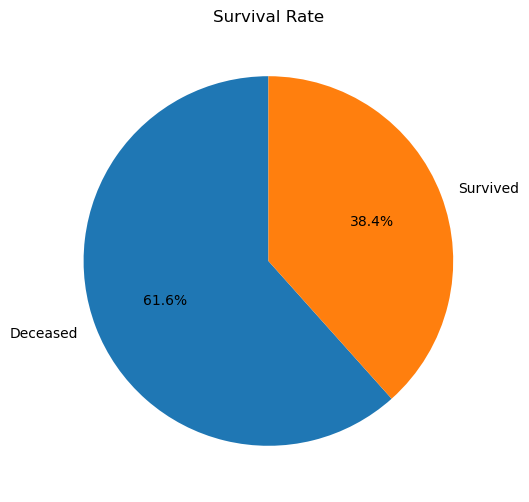
다안: 훌륭해! 그래프를 통해 생존율을 더 직관적으로 이해할 수 있게 됐네. 파이그래프를 보면 승객들의 생존 여부를 한눈에 파악할 수 있어:
전체 승객 중 61.6%가 사망했어
생존한 승객은 38.4%야
프롬: 이렇게 그래프로 보니까 훨씬 이해가 잘 되네요! 많은 사망자가 있었군요… 61.6%가 사망했다는 건 약 3분의 2에 가까운 승객들이 그날 밤 배와 함께 가라앉았다는 의미네요.
다안: 그래, 이는 앞서 describe() 함수로 확인했던 생존율과 정확히 일치해. 시각화를 통해 보니 생존자가 사망자보다 훨씬 적다는 것을 더 직관적으로 이해할 수 있네. 그날 밤 타이타닉호에서 벌어진 비극의 규모를 이 그래프가 잘 보여주고 있어.
숫자로 된 정보들 사이의 관계 분석#
프롬: 이제 각 변수들 사이의 관계를 알아보고 싶어요. 특히 어떤 변수가 생존과 가장 관련이 있는지 궁금해요.
다안: 좋은 생각이야! 나이, 요금, 객실 등급 같은 숫자로 된 정보들이 서로 어떤 관계를 가지고 있는지 알아보는 것은 중요해. 이러한 관계를 시각화하는 좋은 방법 중 하나가 ‘히트맵(heatmap)’이야.
프롬: 히트맵이 뭔가요? 어떻게 생겼나요?
다안: 히트맵은 두 정보 사이의 상관관계를 색상으로 표현하는 그래프야.
1에 가까울수록 강한 양의 상관관계 (한 특성이 증가하면 다른 특성도 증가)
-1에 가까울수록 강한 음의 상관관계 (한 특성이 증가하면 다른 특성은 감소)
0에 가까울수록 상관관계가 약함 (두 특성이 거의 관련이 없음)
프롬: 그럼 히트맵으로 변수들 사이의 관계를 확인해볼게요!
# 프롬프트
숫자로 된 정보들 사이의 관계를 보여주는 히트맵을 그려줘
코더블: 저는 seaborn 라이브러리를 사용해서 히트맵을 만들어볼게요. 먼저 수치형 변수들만 선택한 다음, 상관계수를 계산하고 히트맵으로 표현할게요.
import seaborn as sns
numeric_cols = train.select_dtypes(include=['number']).columns
corr_matrix = train[numeric_cols].corr()
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix,
annot=True, # 상관계수 숫자 표시
center=0, # 0을 중심으로 색상 표시
cmap='coolwarm', # 파란색-흰색-빨간색 색상맵 사용
fmt='.2f', # 소수점 둘째자리까지 표시
square=True, # 정사각형 형태로 표시
vmax=1, # 최대값 설정
vmin=-1) # 최소값 설정
plt.title('Correlation between Numeric Features')
plt.show()
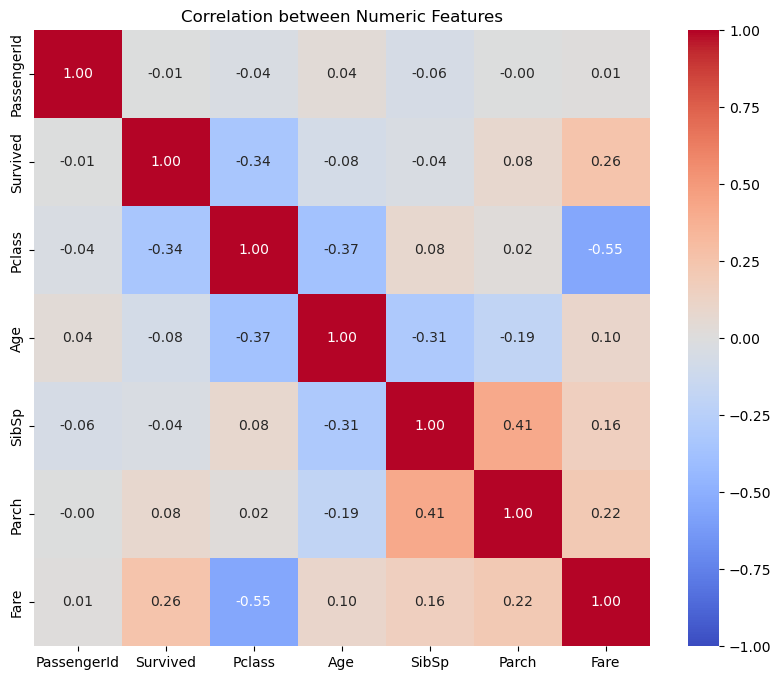
프롬: 와, 이게 바로 히트맵이군요! 빨간색과 파란색이 서로 다른 관계를 나타내는 것 같은데, 어떻게 해석해야 할지 잘 모르겠어요. 0.26이나 -0.55 같은 숫자들이 정확히 무슨 의미인가요?
다안: 히트맵 해석에 대해 더 설명해줄게. 상관계수 값은 -1에서 1 사이의 숫자로 두 변수 간의 관계 강도를 나타내:
💡 상관계수 해석 가이드
0.7 ~ 1.0: 매우 강한 양의 상관관계 (거의 비례)
0.4 ~ 0.7: 상당한 양의 상관관계
0.2 ~ 0.4: 약한 양의 상관관계
-0.2 ~ 0.2: 거의 상관관계 없음
-0.4 ~ -0.2: 약한 음의 상관관계
-0.7 ~ -0.4: 상당한 음의 상관관계
-1.0 ~ -0.7: 매우 강한 음의 상관관계 (거의 반비례)
색상은 관계의 방향을 나타내는데, 빨간색은 양의 상관관계(함께 증가), 파란색은 음의 상관관계(하나 증가하면 다른 하나는 감소)를 의미해.
프롬: 아하! 이제 이해가 되네요. 그럼 생존(Survived)과 다른 변수들 사이의 관계를 보면 어떤 걸 알 수 있나요?
다안: 좋은 질문이야! 생존(Survived)과 다른 정보들의 관계를 살펴보면:
객실 등급(Pclass)과는 뚜렷한 음의 관계(-0.34): 등급이 높을수록(숫자가 작을수록) 생존 확률이 높았어
요금(Fare)과는 뚜렷한 양의 관계(0.26): 비싼 요금을 낸 승객일수록 생존 확률이 높았어
나이(Age)와는 거의 관계가 없음(-0.07): 히트맵에서 흰색에 가까운 색상이 이를 잘 보여주지
코더블: 다른 관계들도 흥미롭네요! 예를 들어, Pclass와 Fare 사이의 상관관계가 -0.55로 꽤 높은데, 이건 역시 1등석일수록 요금이 비쌌다는 걸 보여주는 거죠?
다안: 맞아! 그 관계도 아주 흥미로워. Pclass와 Fare 사이의 음의 상관관계는 1등석(Pclass=1)일수록 요금이 비쌌다는 걸 통계적으로 증명하는 거지. 이런 관계들을 이해하는 것이 데이터 분석의 핵심이야.
프롬: 그럼 정리하자면, 객실 등급과 요금은 생존과 꽤 강한 관계가 있고, 나이는 별로 상관이 없다는 거군요. 그런데 왜 객실 등급과 요금이 생존과 관련이 있었을까요?
다안: 매우 통찰력 있는 질문이야! 이건 타이타닉호의 구조 및 당시 사회적 상황과 관련이 있어. 1등석은 배의 상층부에 위치해서 구명보트에 접근하기 쉬웠고, 승무원들의 안내도 더 많이 받았을 거야. 또한 당시 사회계층에 따라 구조 우선순위가 달랐을 가능성도 있지. 이런 역사적, 사회적 맥락을 데이터를 통해 확인할 수 있다는 게 데이터 사이언스의 매력이야.
객실 등급별 생존율 분석#
프롬: 히트맵을 보니까 객실 등급과 생존이 관련이 있다고 했잖아요. 이걸 좀 더 직접적으로 볼 수 있는 방법은 없을까요? 각 등급별로 정확히 몇 퍼센트가 생존했는지 알고 싶어요.
다안: 좋은 질문이야! 히트맵에서는 전체적인 경향성만 볼 수 있지만, 각 등급별 생존율을 직접 계산해서 시각화할 수도 있어. 막대그래프로 표현하면 좀 더 직관적으로 이해할 수 있을 거야.
코더블: 이번에는 제가 먼저 코드로 만들어보겠습니다. 실제 구현 방법을 보면 프롬프트 작성에도 도움이 될 것 같아요.
pclass_survival = train.groupby('Pclass')['Survived'].mean()
plt.figure(figsize=(8, 6))
sns.barplot(x=pclass_survival.index, y=pclass_survival.values)
plt.title('Survival Rate by Passenger Class')
plt.xlabel('Passenger Class')
plt.ylabel('Survival Rate')
plt.xticks(ticks=[0,1,2], labels=['1st','2nd','3rd'])
plt.show()
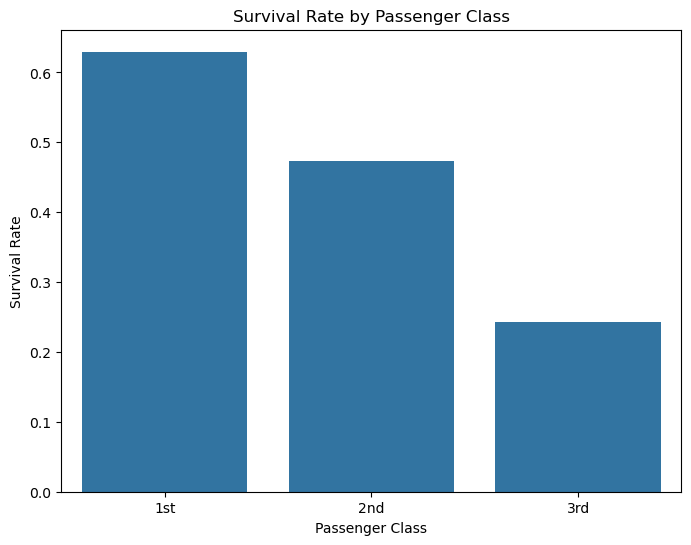
프롬: 우와, 막대그래프로 보니 차이가 확실히 보이네요! 저도 프롬프트로 만들어볼게요.
# 프롬프트
객실 등급(1등석, 2등석, 3등석)에 따라 생존율이 어떻게 다른지 막대그래프로 보여줘
다안: 좋아! 이제 객실 등급별 생존율을 시각적으로 비교할 수 있네. 하지만 정확한 수치를 알기는 좀 어렵지? 조금 더 정확한 값을 보려면 인터랙티브한 그래프가 도움이 될 거야.
프롬: 인터랙티브한 그래프요? 그게 뭔가요?
다안: 인터랙티브한 그래프는 마우스를 가져다 대면 정확한 수치를 보여주는 그래프야. Plotly라는 라이브러리를 사용하면 이런 그래프를 만들 수 있어.
코더블: 제가 Plotly로 인터랙티브 그래프를 만들어볼게요. 이렇게 하면 각 막대에 마우스를 올렸을 때 정확한 생존율을 볼 수 있어요. 참고로 Plotly를 처음 사용하는 경우 ‘pip install plotly’로 설치가 필요할 수 있어요.
import plotly.express as px
# Pclass별 생존율 계산
survival_rates = train.groupby("Pclass")["Survived"].mean().reset_index()
# Plotly를 사용한 막대 그래프 생성
fig = px.bar(
survival_rates,
x="Pclass",
y="Survived",
title="Pclass별 생존율",
labels={"Pclass": "객실 등급", "Survived": "생존율"},
)
# X축을 category 타입으로 설정하여 1, 2, 3만 표시
fig.update_layout(xaxis=dict(type="category"))
# 그래프 표시
fig.show()
프롬: 와! 정확한 숫자를 볼 수 있네요! 1등석은 63%, 2등석은 47%, 3등석은 24%라니… 1등석과 3등석의 생존율이 거의 3배 차이가 나네요! 왜 이렇게 차이가 많이 났을까요?
다안: 여러 가지 이유가 있을 수 있어. 우선 1등석은 배의 상층부에 위치해서 구명보트에 접근하기 쉬웠을 거야. 또한 1등석 승객들은 선원들의 안내를 더 빨리 받았을 가능성도 높아. 그리고 앞서 히트맵에서 봤듯이, 객실 등급은 다른 특성들과도 관련이 있어. 예를 들어 1등석에는 여성 승객의 비율이 더 높았을 수도 있지.
코더블: 타이타닉호의 구조도 영향을 미쳤을 것 같아요. 3등석은 배의 하부에 있어서 침수가 시작됐을 때 탈출하기 더 어려웠을 테니까요.
다안: 맞아, 좋은 지적이야! 배의 구조와 위치도 중요한 요소였을 거야. 3등석은 배의 하부, 특히 물이 먼저 차오르는 곳에 위치했고, 복잡한 구조 때문에 탈출 경로도 더 복잡했을 거야.
프롬: 데이터를 통해 타이타닉의 비극을 더 자세히 이해할 수 있게 된 것 같아요! 객실 등급별 생존율 차이가 이렇게 극명하다니 놀랍네요.
다안: 그래, 지금까지 우리는 타이타닉 생존자 데이터를 다양한 방법으로 살펴봤어. 수치형 데이터의 분포와 관계를 파악하고, 특히 객실 등급과 생존율의 관계를 자세히 분석했지.
다음 시간에는 이렇게 분석한 데이터를 바탕으로 첫 번째 생존자 예측 모델을 만들어볼 거야. 이 모델은 오늘 발견한 패턴들을 학습하여 앞으로 어떤 특성을 가진 승객이 생존했을지 예측하게 될 거야. 비록 단순한 모델이지만, 이를 통해 머신러닝의 기본적인 과정을 이해할 수 있을 거야.
코더블: 다음 시간이 기대되네요! 이번에 배운 상관관계를 활용해서 모델을 만들면 성별만 고려했을 때보다 더 정확한 예측이 가능하지 않을까요?
프롬: 저도 다른 변수들과 생존율의 관계도 더 살펴보고 싶어요. 특히 나이와 생존율, 요금과 생존율 같은 관계요!
다안: 좋은 생각들이야! 맞아, 우리가 살펴본 것처럼, 다른 수치형 특성들도 생존율과 관련이 있을 수 있어. 다음 특성들에 대해서도 직접 시각화해보면 재미있는 패턴을 발견할 수 있을 거야:
SibSp(형제자매 수)와 생존율의 관계
Parch(부모자녀 수)와 생존율의 관계
프롬: 집에 가서 직접 해볼게요! 이제 프롬프트로 그래프도 만들 수 있으니까 재미있을 것 같아요!
코더블: 저는 각 변수별로 시각화하는 함수를 만들어서 코드를 더 효율적으로 작성해볼게요. 다음 시간에 공유할게요!
데이터 속 숨은 이야기
타이타닉호의 최고가 승객: Charlotte Cardeza
데이터에서 가장 비싼 요금인 512파운드(현재 가치로 약 1억 3천만원)를 지불한 승객은 Charlotte Cardeza였습니다. 그녀는 펜실베니아 저먼타운의 호화로운 저택 ‘Montebello’에 거주하던 58세의 부유한 미국인이었습니다.
Charlotte은 아들 Thomas와 메이드 Anna Ward와 함께 Cherbourg에서 타이타닉호에 탑승했습니다. 그들이 사용한 B51/53/55번 객실은 배에서 가장 비싼 스위트룸 중 하나였습니다. 그녀의 일행은 무려 14개의 트렁크, 4개의 여행가방, 3개의 화물 상자를 가지고 탑승했는데, 후에 이 분실 물품들에 대해 36,567파운드의 보상을 청구했다고 합니다. 다행히 Charlotte과 그녀의 일행은 3번 구명보트를 타고 무사히 구조되었습니다.
그녀의 사례는 타이타닉호 1등실의 최상층 서비스가 어떠했는지, 그리고 당시 상류층의 호화로운 여행 문화를 잘 보여줍니다. 또한 우리가 앞서 히트맵에서 발견한 “높은 요금과 생존 확률의 상관관계(0.26)”를 보여주는 대표적인 사례이기도 합니다.